
一、集群化方案
1、MySQL应用的演化
MySQL与HBase说到最核心的点,是一种数据存储方案。方案本身没有对错、没有好坏,只有合适与否。相信多数公司都与MySQL有着不解之缘,部分学校的课程甚至直接以SQL语言作为数据库讲解。我想借自身经历,先来谈谈MySQL应用的演化。
只有MySQL
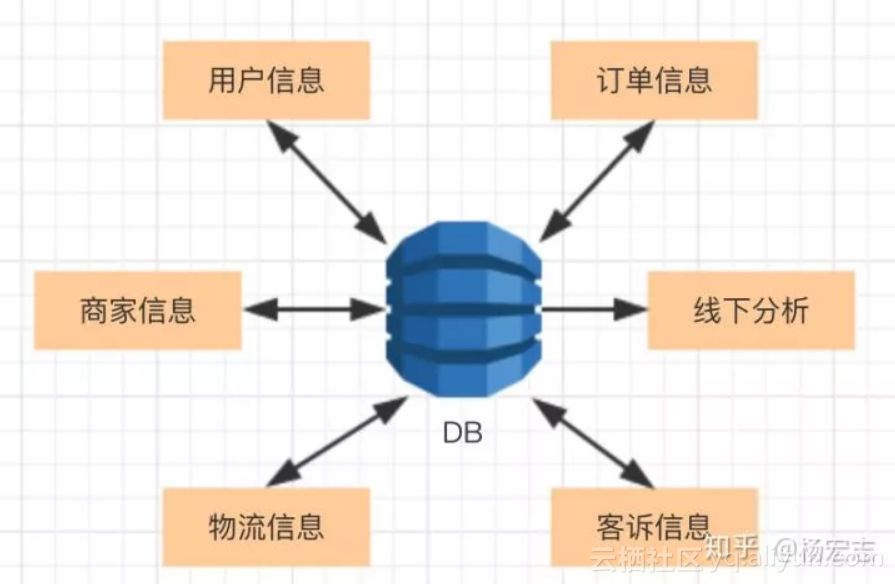
笔者之前曾在一家O2O创业公司工作,公司所有数据都存储在同一个MySQL里,而且没有任何主备方案。相信这是很多初创公司会用到的一个典型解决办法,当时这台MySQL为用户、订单、物流服务,同时也为线下分析服务。
单实例的问题:
![]() 一旦MySQL挂了,服务全部停止;
一旦MySQL挂了,服务全部停止;
主从方案
随着业务增加,单个DB是无法承载这么多请求的。于是就有了主从复制、读写分离的解决方案。
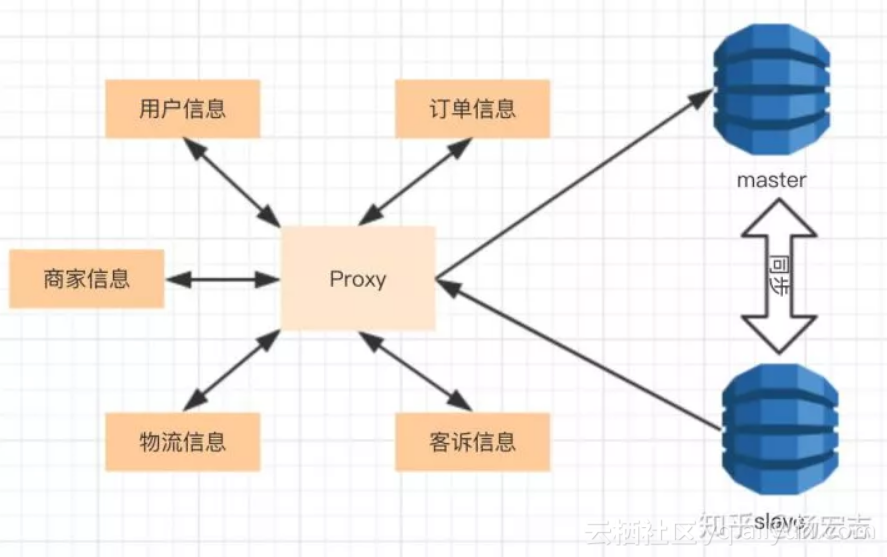
master只负责写请求,slave同步master用来服务读请求:
![]() 为了扩展读能力可以增加多个slave;
为了扩展读能力可以增加多个slave;
主从功能的问题:
![]() 需要增加管理Proxy层,分配写请求、读请求;
需要增加管理Proxy层,分配写请求、读请求;
垂直拆分
业务继续增长,master甚至无法承载所有的写请求,数据库需要按业务拆分。
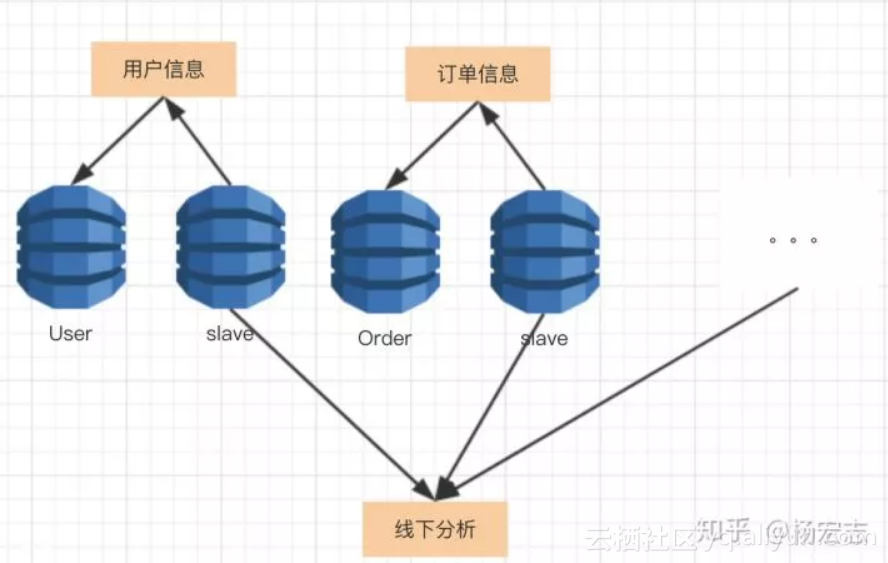
垂直拆分的问题:
![]() 线下分析,需要在业务代码里join各个表。因为拆成多个库,已经无法join了。
线下分析,需要在业务代码里join各个表。因为拆成多个库,已经无法join了。
水平拆分
业务继续增长,订单表有大量的并发写入,而且已经有了几千万行数据。
![]() 单个库无法承载大量的并发写入;
单个库无法承载大量的并发写入;
参考:大众点评订单系统分库分表实践
https://zhuanlan.zhihu.com/p/24036067
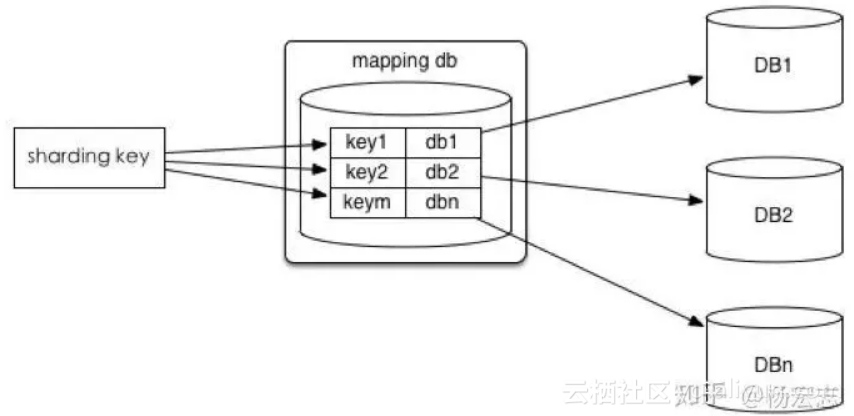
水平分库/分表带来的问题:
![]() 维护map方案;
维护map方案;
![]() 扩容:需要再次水平拆分的:修改map,迁移数据……
扩容:需要再次水平拆分的:修改map,迁移数据……
2、MySQL的问题
MySQL的主要瓶颈,单机单进程。CPU有限、内存/磁盘功能、连接数有限、网卡吞吐有限……
集群的限制点:
![]() 关系型数据库,纵向的外键相互join;
关系型数据库,纵向的外键相互join;
范式参考链接:https://zhuanlan.zhihu.com/p/20028672
![]() 数据库事务性,基于单机的锁机制,无法扩展到集群中使用;
数据库事务性,基于单机的锁机制,无法扩展到集群中使用;
集群的方案:
![]() 放弃部分功能,辅助索引检索、join、全局事务性、聚合函数等;
放弃部分功能,辅助索引检索、join、全局事务性、聚合函数等;
![]() 服务稳定性:主节点挂了,Proxy会将从节点升级为主节点;从节点挂了会被其它从节点替换。
服务稳定性:主节点挂了,Proxy会将从节点升级为主节点;从节点挂了会被其它从节点替换。
3、HBase集群化解决方案
水平拆分:
![]() region:拆分后的子表;
region:拆分后的子表;
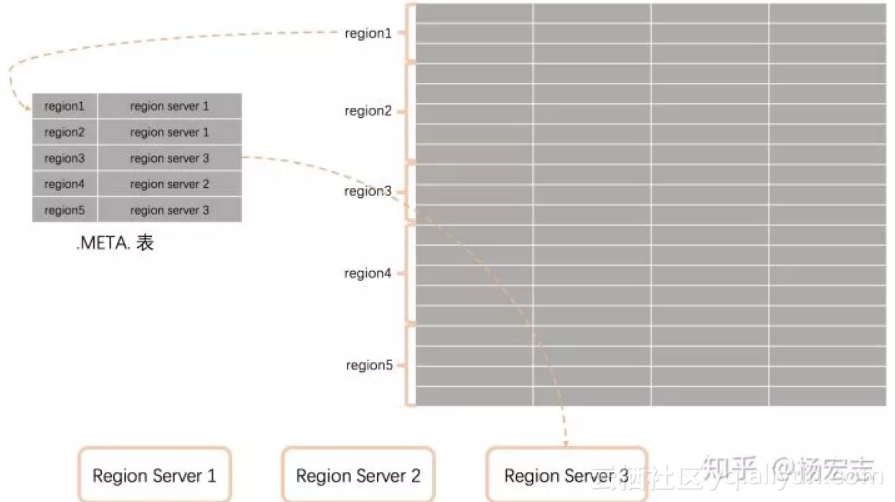
单个region过大,RegionServer会将region均分为两个(自动、手工)。然后更新.META.表。
扩容方案:
RegionServer向HMaster汇报状态。HMaster为RegionServer负载均衡,调整其负责的region 。
增/删RegionServer后,会为重新调整region的分配方式。
服务稳定性:
RegionServer只是计算单元,挂掉后Hmaster可以随便再找一个节点代替坏节点服务。
事务性:
HBase只保证行级事务,单行数据肯定存在同一台机器(单机事务很好做)。
备份容灾:
![]() 数据使用HDFS存储,多复本,任何一个复本挂掉都不影响功能;
数据使用HDFS存储,多复本,任何一个复本挂掉都不影响功能;
![]() RegionServer只是计算单元,挂掉后不影响服务。
RegionServer只是计算单元,挂掉后不影响服务。
二、性能取舍
1、数据请求流程
HBase:
![]() Client会通过Zookeeper定位到 .META. 表;
Client会通过Zookeeper定位到 .META. 表;
MySQL:
![]() Client通过Proxy,查找需要连接的MySQL实例,连接并进行读写。
Client通过Proxy,查找需要连接的MySQL实例,连接并进行读写。
Rquest的路由流程,MySQL与HBase基本一致,那么RegionServer与MySQL的性能差异如何呢?
2、Hbase写得快
新增
为什么MySQL建议自增主键?(MySQL随机插入的代价)
![]() 主键索引是有序的B+树结构,新增条目的ID肯定是最大的,新增给B+结构带来的调整最小;
主键索引是有序的B+树结构,新增条目的ID肯定是最大的,新增给B+结构带来的调整最小;
辅助索引,插入基本是随机的:
![]() 插入条目,可能会引起B+树结构很大的调整。
插入条目,可能会引起B+树结构很大的调整。
HBase可以随机插入:
![]() HBase的所有插入只是写入内存memstore,只保证内存数据的有序即可(很快、很容易);
HBase的所有插入只是写入内存memstore,只保证内存数据的有序即可(很快、很容易);
修改
MySQL数据变化引起存储变动:
![]() 数据块大小变化:磁盘空间不足,可能需要调整磁盘存储结构,引起大量的磁盘随机读写;
数据块大小变化:磁盘空间不足,可能需要调整磁盘存储结构,引起大量的磁盘随机读写;
HBase直接将变化写入到memstore,没有其它开销。
删除
MySQL数据删除:
![]() 直接操作B+树的节点,肯定需要刷新磁盘;
直接操作B+树的节点,肯定需要刷新磁盘;
HBase只是在memstore记录删除标记,没有其它开销。
3、结论
HBase写入内存+后台刷盘(最多是WAL,磁盘顺序写);MySQL需要维护B+树,大量的磁盘随机读写。
MySQL要求尽量追加写(自增 ID),速度较慢;HBase可以随机插入,速度很快。
MySQL读得快
MySQL数据是本地存储的,HBase是基于HDFS,有可能数据不在本地。
B+ 树天然的全局有序
![]() 根据主键查询,可以快速定位到数据所在磁盘块,只需要极少的磁盘IO即可拿到数据:通过缓存高层节点,主健查询只需要一次磁盘IO就可拿到数据;MySQL单表行数一般建议不会超过2千万,千万行以下的大表,B+树只需2~3层即可;
根据主键查询,可以快速定位到数据所在磁盘块,只需要极少的磁盘IO即可拿到数据:通过缓存高层节点,主健查询只需要一次磁盘IO就可拿到数据;MySQL单表行数一般建议不会超过2千万,千万行以下的大表,B+树只需2~3层即可;
![]() 辅助
辅助
HBase只有局部信息,没有辅助索引
![]() 查询会优先查找memstore,如果没有会查找Hfile(存储结构类似B+树)。如果第一个Hfile中没有所需的信息,则需要去第二、第三个Hfile中查询;如果查询的数据恰好在memstore,第一个Hfile,HBase会优于MySQL;平均下来,HBase读性能一般。减少Hfile数据以提速,小的HFile合并成大的HFile文件。这种存储结构叫LSM树(Log-structured merge-tree);
查询会优先查找memstore,如果没有会查找Hfile(存储结构类似B+树)。如果第一个Hfile中没有所需的信息,则需要去第二、第三个Hfile中查询;如果查询的数据恰好在memstore,第一个Hfile,HBase会优于MySQL;平均下来,HBase读性能一般。减少Hfile数据以提速,小的HFile合并成大的HFile文件。这种存储结构叫LSM树(Log-structured merge-tree);
MySQL成也B+,败也B+;HBase成也LSM,败也LSM。
4、附录
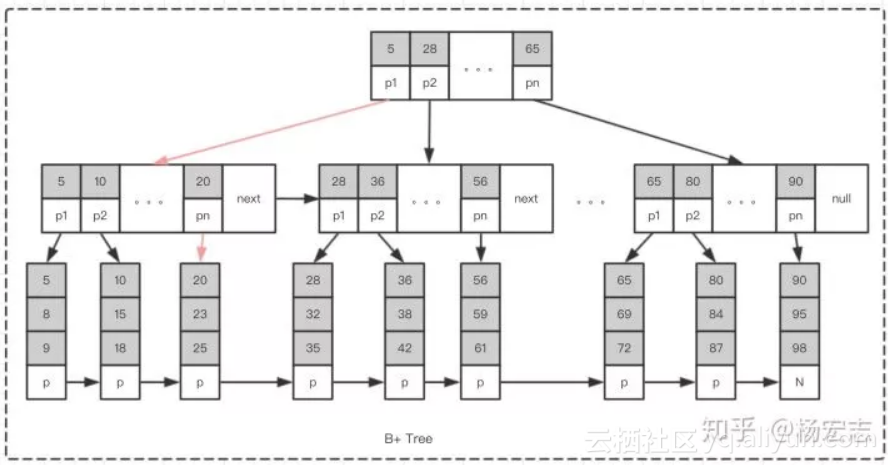
B+ 树
查询“值为25”的节点,只需要2次定位即可。
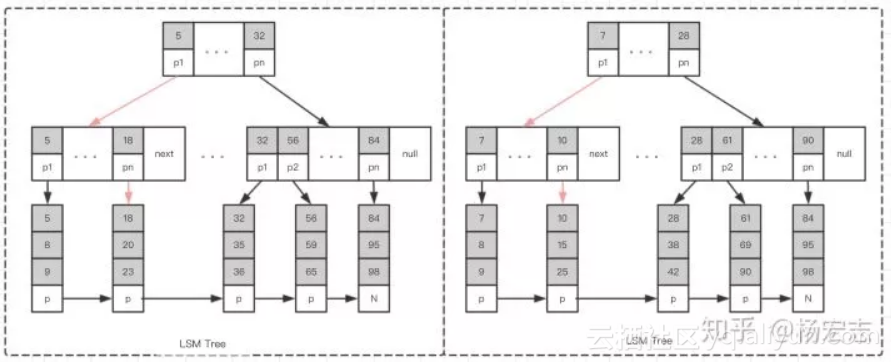
LSM树
查询“值为25”的节点,只需要4次定位即可。
三、优化思路
1、HBase优化点 (主要是读)
异步化
![]() 后台线程将memstore写入Hfile;
后台线程将memstore写入Hfile;
数据就近
![]() blockcache,缓存常用数据块:读请求先到memstore中查数据,查不到就到blockcache中查,再查不到就会到磁盘上读,把最近读
blockcache,缓存常用数据块:读请求先到memstore中查数据,查不到就到blockcache中查,再查不到就会到磁盘上读,把最近读